
课程视频地址 https://www.youtube.com/watch?v=rmVRLeJRkl4&list=PLoROMvodv4rOSH4v6133s9LFPRHjEmbmJ
什么是NLP?
NLP就是自然语言处理natural language processing,基本上解决的就是计算机怎么理解人类语言的问题,实际应用中包括文本胜场,文本分类,机器翻译,甚至最近很火的ChatGPT等等需求都是由NLP完成的。
我在深度学习兴起前后,比较系统的学过NLP,比较传统的中文的NLP问题是刚才那些问题加上一个分词问题。我以前做过搜索服务,分词是我们很关心的问题。
Word2vec火起来的时候,我已经没怎么玩NLP了。
最近又开始有兴趣重新学在深度学习下的NLP,主要是由ChatGPT的大火以及它目前达到的水平造成的。
第一课主要是介绍了Word Vectors的概念。
我印象最深刻的是老师引用的,John Rupert Firth的一句话,他是,英国语言学家,伦敦学派创始人。
You shall know a word by the company it keeps.
John Rupert Firth 1957:11
这句话的意思是说,了解一个词应该看它和什么其他的词一起出现。换句话说,就是了解一个词要看它的上下文,它经常出现的上下文。
其实传统的NLP也是把一个词当作一个向量来处理的,但是这是一个稀疏的向量,比如我有1万篇语料,那么我们就把买个词表示成一个1万维的向量,每一维是0还是1,视这个词是否出现在这个语料里决定。
比如,下面的表示就代表,motel出现在了第11个语料,而hotel出现在第9个语料里。

这样的方法其实解决了很多传统思路下的NLP问题。
但是深度学习下的NLP的开始是把一个词的含义用它前后出现的词来理解,形成Word Vectors。就像John Rupert Firth说的那样。
John Rupert Firth说的这句话是在1957年,但是最近几年,Word Vectors、深度学习才真的能把这样的认识变成计算机的数据机构,变成可以计算的东西。这让我想到,我们可以有很多灵感,但是这些东西是否能给人类带来贡献,需要科技到达某个水平去把我们的灵感变成现实,或者释放出巨大的能量,或者干脆告诉我们这些根本就是错的。光有这些灵感并无用。
另外John Rupert Firth的这句话,我认为跟我倡导的学习语言的理念其实也很接近。你背单词,你背词典的解释,其实是一种机械的对词语的理解。事实上,我们对母语的大多数词汇的理解,都是在使用中,在它的使用场景中理解的。我们有时候可以不知道一个词在词典中的确切意思,但是因为它每每都出现在某个上下文里面,我们就可以自然的获得对这个词汇的理解。
代码
老师提供了如下的Python代码,
import numpy as np
%matplotlib inline
import matplotlib as plt
plt.style.use('ggplot')
from sklearn.decomposition import PCA
import gensim.downloader as api
from gensim.models import KeyedVectors
model = api.load("glove-wiki-gigaword-100")这个代码,使用了Gensim(1)。Gensim并不是深度学习哭,但是包含了word vector的实现。数据用了斯坦福自己的GloVe(2)的word vector数据。
加载了model以后,就可以用model来观察和研究词之间的关系。比较简单的,我们可以看跟面包关系比较紧密的东西有什么:
model.most_similar(["bread"]
[('flour', 0.7654520869255066),
('baked', 0.7607272863388062),
('cake', 0.7605516910552979),
('loaf', 0.7457114458084106),
('toast', 0.7397798895835876),
('cheese', 0.7374635338783264),
('potato', 0.7367483973503113),
('butter', 0.7279618978500366),
('potatoes', 0.7085272669792175),
('pasta', 0.7071877717971802)]输出的这些词分别是flour – 面粉, baked – 烘焙, cake – 蛋糕 loaf – 一条面包, toast – 烤面包, cheese – 奶酪, potato – 土豆, butter – 黄油, potatoes – 土豆, pasta – 面条。
我们也可以看跟coffee关系紧密的是什么:
model.most_similar(["coffee"]
[('tea', 0.77326899766922),
('drinks', 0.7287518978118896),
('beer', 0.7253385186195374),
('cocoa', 0.7026591300964355),
('wine', 0.7002726793289185),
('drink', 0.6990923881530762),
('corn', 0.6825440526008606),
('sugar', 0.6775094270706177),
('bread', 0.6727856993675232),
('fruit', 0.667149007320404)]但是,因为这些都是word vector词向量,向量是可以进行运算的,在空间上加减可以得到很有意思的结果。下图的例子是
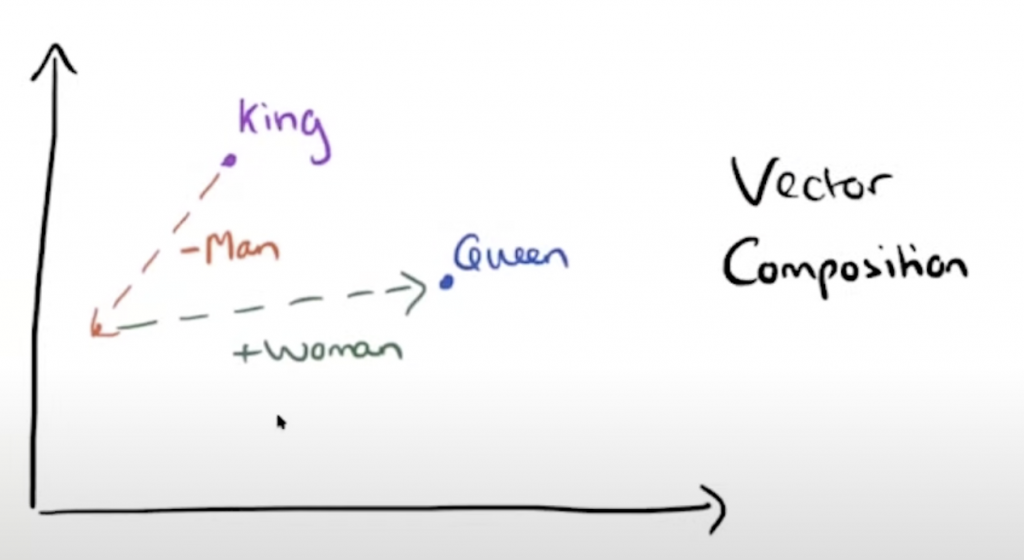
我们知道king的向量和man的向量有关系,如果我们把king的向量减去一个man得到了一个新的起点,然后加上一个woman,结果就可能会得到gueen的结果。代码如下:
model.most_similar(positive=["king","woman"],negative=["man"])
[('queen', 0.7698541283607483),
('monarch', 0.6843380331993103),
('throne', 0.6755736470222473),
('daughter', 0.6594556570053101),
('princess', 0.6520534157752991),
('prince', 0.6517034769058228),
('elizabeth', 0.6464518308639526),
('mother', 0.631171703338623),
('emperor', 0.6106470823287964),
('wife', 0.6098655462265015)]most_similar的positive参数里面放上两个词,king和woman等于这两个向量相加,negative放入man,等于在结果向量减去man。结果第一个就是queen。
类似的研究或者游戏,我们可以继续做,都很好玩。
model.most_similar(positive=["coffee","china"],negative=["usa"])
[('tea', 0.6365849375724792),
('fruit', 0.6253646016120911),
('chinese', 0.5799036622047424),
('food', 0.5783675312995911),
('grain', 0.577540397644043),
('vegetables', 0.5578237771987915),
('prices', 0.5492344498634338),
('fruits', 0.5417575836181641),
('export', 0.5401189923286438),
('vegetable', 0.5384897589683533)]model.most_similar(positive=["king","china"],negative=["england"])
[('jiang', 0.6718781590461731),
('chinese', 0.657663106918335),
('wu', 0.6562906503677368),
('li', 0.6415701508522034),
('zhu', 0.6260422468185425),
('liu', 0.6097914576530457),
('beijing', 0.6078009605407715),
('qin', 0.6032587289810181),
('zemin', 0.6009712815284729),
('chen', 0.5993086099624634)]model.most_similar(positive=["president","china"],negative=["usa"])
[('jiang', 0.7173388600349426),
('hu', 0.7164437770843506),
('government', 0.6859283447265625),
('jintao', 0.6816513538360596),
('zemin', 0.6663808822631836),
('chinese', 0.6555445194244385),
('chen', 0.6504189372062683),
('beijing', 0.6466312408447266),
('taiwan', 0.627478837966919),
('administration', 0.6196395754814148)]Notes:
- Gensim是一个用于自然语言处理(NLP)的开源 Python 库。它提供了用于文本相似性分析、主题模型、文本转化和聚类的工具。Gensim 借鉴了许多有效的 NLP 技术,包括 Latent Semantic Analysis(LSA)、Latent Dirichlet Allocation(LDA)和 Random Projections(RP)。
Gensim 的目标是为用户提供一个简单易用的工具,帮助用户在文本数据上执行高效的 NLP 任务。 Gensim 使用简单的命令行界面,使用户可以轻松地处理大型文本集合,并使用少量的代码实现复杂的 NLP 任务。 - GloVe(Global Vectors for Word Representation)是一种用于词嵌入(word embedding)的技术。它通过在语料库中统计每个单词和其他单词的共现次数,然后通过最小二乘法将单词映射到低维空间的向量(即词嵌入)的过程来工作。
GloVe的优势在于它能够保留单词之间的关系,这使得它很适合用于自然语言处理(NLP)任务,例如文本分类、机器翻译等。它也比较通用,能够应用于多种语言,并且计算效率高。GloVe是一种流行的词嵌入技术,并且已经被广泛应用于自然语言处理领域。它能够提供有效且较为通用的词嵌入,是许多自然语言处理系统的首选。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~