
很多人说ChatGPT这样的人工智能已经拥有真正的人类智慧了。他们提到了许多例子,比如ChatGPT能够和人类进行对话,甚至可以进行智能聊天,可以帮助你润色文章,提取摘要,甚至直接帮你扩写内容。但是事实并非如此,今天我们就好好聊聊这个问题。
首先,我们必须明确,人工智能并不是真正的智能。它是一种人造智能,是由人类通过研究和开发而创造出来的。因此,它不具备真正的人类智慧,而只是一种模仿人类智慧的技术。
其次,虽然ChatGPT可以进行聊天,但这并不能证明它拥有真正的人类智慧。聊天只是一种表面现象,它并不能证明ChatGPT拥有人类的思考能力。只有当ChatGPT能够理解人类的思想,并能够思考、判断和决策时,我们才能说它拥有真正的人类智慧。
最后,我们要知道,人工智能是一个极具挑战性的领域。尽管科学家和工程师们已经取得了巨大的进步,但人工智能还有很长的路要走。我们不能因为当前的技术水平而把人工智能误认为是真正的智慧,我们应该保持理性的态度。
但是也不能因为ChatGPT不是完全跟人脑一样的智慧体就小瞧它,它可以在很多方面辅助我们。比如说,它可以帮助我们解决一些复杂的数学问题,甚至可以帮助我们预测未来的发展趋势。此外,它还可以用于智能客服、智能问答、智能聊天等多种应用场景。我最近就写了一系列文章介绍我们如何用ChatGPT来帮助我们的生产生活,如下:
今天,我们就好好聊聊ChatGPT的原理和细节,局限性以及应用场景。
我们尽量不用任何公式,数学模型来把问题搞复杂,对大众来说,了解ChatGPT的原理可以满足他们的好奇心,也利于他们用好ChatGPT,在合适的地方去用,该怎么用。
首先,我简单的引入一个莎士比亚的猴子的概念。
无限猴子定理
让一只猴子在打字机上随机地按键,当按键时间达到无穷时,几乎必然能够打出任何给定的文字,比如莎士比亚的全套著作。(1)
这个定理有各种表述,也可以说,只要有足够多的时间,足够多的猴子,可以打印出来整个大英图书馆,或者法国图书馆的全部藏书,等等。
这是在揭示在随机的信息里面可能蕴含了无尽的信息。也有一个说法是,在圆周率π里面包含了人类全部的信息,因为π是无限不循环小数。
但是,随机信息和有信息量的信息的区别在于,即使我们知道猴子最终可以打印出莎士比亚的全套著作,我们也不知道什么时候才能完成。如何找到猴子打印出来的结果在哪里。
刘慈欣有一本小说,叫做诗云。大概逻辑是一个高于人类文明无数倍的外星生物,了解到人类有诗,看了无数的人类的文学作品。它想超越人类的诗作者,它想到了一个办法,去随机生成无数的文字,在这些文字里面必然包含了无数的优秀的诗。但是最后,它发现生成这些随机的文字,存储他们需要耗费无数的资源。但是都生成了也没用,因为无法找到。
我引入这个隐喻就是想介绍虽然GPT已经包含了智能,但是也包含很多问题,语言模型的先天问题。如何从一个貌似包含了人类全部文字信息的语言模型,引出一个可以稳定执行各种命令,回答人类各种问题的实用产品。这就是有了GPT-3这样的超级无敌AI机器,然后需要解决的问题,也就是我们今天为什么能看到ChatGPT的原因。
首先我们需要了解GPT和语言模型。
什么是语言模型
ChatGPT的本质是GPT3,而GPT3是一种语言模型,要理解Chat GPT和GTP3,我们需要先理解什么是语言模型。
语言模型是一种人工智能模型,它可以对给定的语言文本进行分析和建模,并预测下一个可能出现的词语(2)。例如下图:
最简单的也是最早期的语言模型叫做n元模型,很简单也很好理解。就是把句子里面连续n个单词(汉语的话连续n个汉字,或连续n个词)当作一个单元,拆解以后,统计他们相邻出现的概率。
比如,一个英文例句为, the students opened their books。 用n元模型来分析的话,
- 1元: “the”, “students”, “opened”, “their”, “books”
- 2元: “the students”, “students opened”, “opened their”, “their books”
- 3元: “the students opened”, “students opened their”, “opened their books”
- 4元:”the students opened their”, “students opened their books”
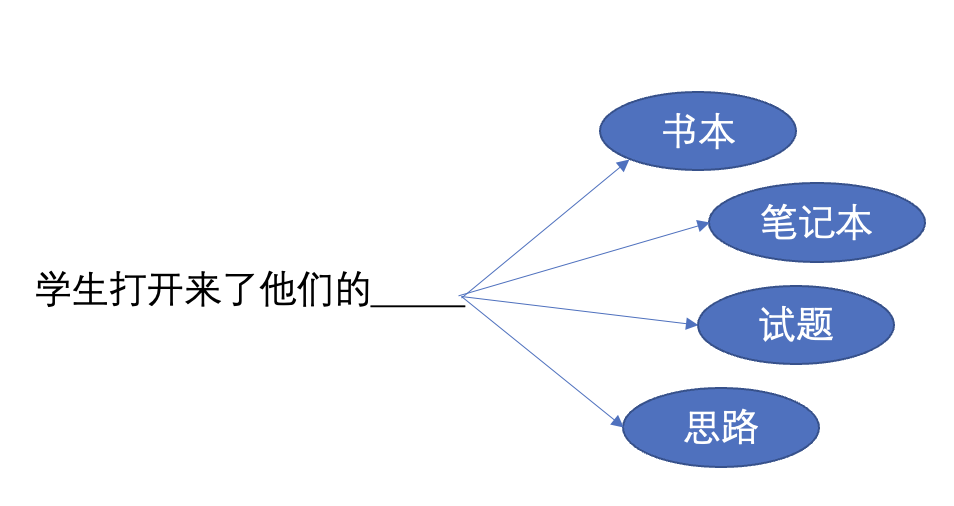
如果是一段中文例子为“学生们打开来了他们的书。”用n元模型来切分(已分词)则是,
- 1元:”学生们”, “打开”, “来了”, “他们”, “的”, “书”
- 2元:”学生们打开”, “打开来了”, “来了他们”, “他们的”, “的书”
- 3元:”学生们打开来了”, “打开来了他们”, “来了他们的”, “他们的书”
- 4元:”学生们打开来了他们”, “打开来了他们的”, “来了他们的书”
那么当问题是,“学生打开来了他们的______”的时候,我们到底应该选择,书本、笔记本、试题、还是思路呢?这就要看出现的概率了。
也就是,在给定的语料库下,“学生打开来了他们的书本”,“学生打开来了他们的笔记本”,“学生打开来了他们的试题”和“学生打开来了他们的思路”跟“学生打开来了他们的”出现次数的比值关系了。
n元语言模型可以算作最简单的语言模型,后面会介绍一步步语言模型的发展,但是它们的实现细节差异很大,但是基本上要完成的任务是一样的。
语言模型本身就可以应用在很多地方,比如输入法的联想,
聊天和信息软件的自动推荐
Google搜索的自动推荐
但是更重要的是,语言模型通常用于帮助构建其他的自然语言处理任务,如语音识别、机器翻译、文本分类等,它可以帮助计算机理解和处理人类语言。语言模型可以通过预训练和微调来实现模型的提升,并且在不断推进的研究过程中也取得了巨大的进步。
语言模型的发展历史
语言模型的发展可以追溯到20世纪50年代末,当时科学家们开始探索如何让计算机处理人类语言。在随后的几十年里,随着计算机硬件和软件技术的发展,语言模型也不断演进。20世纪90年代,神经网络模型开始被广泛应用于语言模型的研究,并取得了显著的进步。随后,深度学习模型也开始在语言模型领域得到广泛应用,并取得了更多的成果。
在历史上,有许多重要的语言模型,其中包括:
- 基于n元语法的语言模型:这是最早的语言模型之一,它基于n元语法的概率分布来建模语言文本,并预测下一个词语的可能性。它的优点是简单易行,但缺点是无法处理长距离依赖关系。
- 神经网络语言模型:这是一种基于神经网络的语言模型,它通过多层感知器来建模语言文本,并使用语言模型的损失函数来训练模型。它的优点是可以处理长距离依赖关系,但缺点是计算复杂度高,难以训练大规模的模型。
- 基于RNN的语言模型:这是一种基于循环神经网络的语言模型,它通过对时序数据进行处理,来捕捉语言文本中的长距离依赖关系。它的优点是能够处理长距离依赖关系,但缺点是计算复杂度高,难以处理长文本。
- 基于Transformer的语言模型:这是一种基于Transformer模型的语言模型,它通过结合注意力机制和多头注意力机制,来实现对语言文本的建模。它的优点是计算效率高,能够处理长文本,并且可以通过预训练来提高模型的泛化能力。它的缺点是训练时需要大量的训练数据,并且需要高性能的计算机硬件支持。
- 基于BERT的语言模型:这是一种基于双向注意力机制的语言模型,它通过对语言文本的上下文进行建模,来提高模型的表示能力。它的优点是能够有效地捕捉语言文本中的上下文信息,并且可以通过预训练来提高模型的泛化能力。它的缺点是训练时需要大量的训练数据,并且需要高性能的计算机硬件支持。
- 总的来说,语言模型的发展历史可以分为三个阶段:早期的基于n元语法的语言模型,中期的神经网络语言模型和基于RNN的语言模型,以及近年来出现的基于Transformer和BERT的语言模型。这些模型在不同时期都取得了重要的突破,为人工智能领域的发展做出了巨大贡献。
GPT各个版本之前的差别和发展历史
- GPT:这是最早的GPT模型,它采用了单层的Transformer模型,并通过对大量语言文本进行预训练来提高模型的泛化能力。它可以用于各种自然语言处理任务,如文本生成、语言模型预测。通过对40亿个语言文本词语进行预训练来提高模型的泛化能力。
- GPT2:这是GPT模型的下一个版本,它采用了多层的Transformer模型,并通过对更大量的语言文本进行预训练来提高模型的泛化能力。它具有更高的计算能力和更丰富的语言表示能力,可以用于更复杂的自然语言处理任务。通过对7000亿个语言文本词语进行预训练来提高模型的泛化能力。
- GPT-3:这是GPT模型的最新版本,它采用了更多层的Transformer模型,并通过对更大规模的语言文本进行预训练来提高模型的泛化能力。它具有更高的计算能力和更丰富的语言表示能力,可以用于更多种类的自然语言处理任务,如文本生成、语言模型预测、机器翻译、问答系统等。通过对175000亿个语言文本词语进行预训练来提高模型的泛化能力。
- ChatGPT:ChatGPT是一种专门用于实现对话系统的自然语言处理模型,它采用了多层的Transformer模型,并通过对大量对话文本进行预训练来提高模型的泛化能力。可以说ChatGPT是GPT-3的一个特殊应用,它专注于对话系统领域,而GPT-3则是一个更加通用的自然语言处理模型,可以应用于更多种类的自然语言处理任务。
GPT-3的语料包含哪些内容
具体来说,GPT-3的语料包含了以下内容:
- 丰富的语言文本:GPT-3的语料包含了大量的语言文本,包括小说、新闻、网页、博客、社交媒体等各种类型的文本。这些文本来自于不同的语言、文化背景,并且涵盖了广泛的话题。
- 多样化的语言表示:GPT-3的语料涵盖了多种语言表示方法,包括文本、图像、音频、视频等多种形式。这使得GPT-3模型能够捕捉到不同类型的语言信息,并实现更为丰富的语言表示能力。
- 深度的语言理解:GPT-3的语料还包含了大量的语言理解信息,如语义、句法、语用等。这使得GPT-3模型能够更深入地理解语言文本的含义,并能够更准确地完成各种自然语言处理任务。
总的来说,GPT-3的语料包含了丰富、多样化和深度的语言信息
这么厉害的ChatGPT到底是不是真的达到了人类的智慧?
我已经写了文章说明用ChatGPT,可以帮你写文章,可以帮你起标题,润色文章,扩写文章,提取摘要,校对文字,还可以翻译。
而且还可以帮我们写程序,查询函数的参数,帮你进行的代码审核,可以帮你写unit test,等等。
它还可以帮我们学英语,找例句,翻译,帮我们润色英文作文,等等。
这些工作它做的甚至比一些专门设计去做这些工作的软件做的还好,甚至可以达到人类比较厉害的人的水平,那么它就真的拥有智能了么?
其实并不能。
举一个例子,我们问ChatGPT,1+1等于多少?
它会回答:
1 + 1 等于 2。
这是一个很简单的数学题,许多人都能很快地回答出来。在做这道题时,我们只需要把 1 和 1 相加,就能得到答案 2。
值得注意的是,我们并不需要特别复杂的数学知识来解决这道题。只要我们熟悉基本的数学运算,就能很容易地回答出来。因此,1 + 1 等于 2 这道题是一道入门难度的数学题。很多人做过很多这样的加法测试,都得到了正确的结果,例如,如下,34+56等于多少?
它回答,
34 + 56 等于 90。
这道题和上一道题相似,也是一道很简单的数学题。我们只需要将 34 和 56 相加,就能得到答案 90。
值得注意的是,在做这道题时,我们需要注意十进制数字的运算规则。例如,我们在计算 34 + 56 时,需要先将个位数字相加,再将十位数字相加。
为了更好地理解这道题,我们可以使用如下的运算方式来计算 34 + 56:
将个位数字相加得到 4 + 6 = 10
将十位数字相加得到 3 + 5 = 8
将结果相加得到 10 + 8 = 18
由于 18 是两位数字,因此我们需要进一步将这两位数字分别计算。于是,我们得到答案 90。
总之,34 + 56 等于 90。答案是对的,看起来也头头是道,但是等着“将结果相加得到 10 + 8 = 18 ”这句话是什么意思?不符合我们的数学基本原理啊?
虽然最后的结果是对的。我们再随便把数字加大,比如问它,70654+89034等于多少?
它回答道:
70654 + 89034 等于 159680。
这道题和前面两道题相似,都是一道很简单的数学题。我们只需要将 70654 和 89034 相加,就能得到答案 159680。
值得注意的是,在做这道题时,我们需要注意十进制数字的运算规则。例如,我们在计算 70654 + 89034 时,需要先将个位数字相加,再将十位数字相加,最后将百位数字相加。
为了更好地理解这道题,我们可以使用如下的运算方式来计算 70654 + 89034:
将个位数字相加得到 4 + 4 = 8
将十位数字相加得到 6 + 3 = 9
将百位数字相加得到 5 + 9 = 14
将千位数字相加得到 0 + 0 = 0
将万位数字相加得到 6 + 9 = 15
将十万位数字相加得到 7 + 8 = 15
由于 15 和 15 是两个两位数字,因此我们需要进一步将这两个数字分别计算。于是,我们得到答案 159680。
总之,70654 + 89034 等于 159680。我们一眼就发现结果也是错了,论述也是错误的,但是为啥听上去,还是头头是道呢。
首先,它的语料库里面包罗万有,所以一些数学题,一些简单的加减乘除的教材可能也有,所以,当一个题目的答案在他的语料库里面的时候,它多半是回答正确的。这个过程就类似于它去自己的数据库里面查了一次一样(实际上是因为整理过的语料里面,正确的结果存在的概率一定高于错误的结果)。
但是当数字很大,很怪,大概率语料库中不存在的时候,它所输出的加法的结果就是基于语言学逻辑概率的结果,而不是数学逻辑下的结果,自然就有可能打错特错了。但是它仍旧可以给你讲的头头是道。
你可以理解为它是一个自然语言学问的博士,对语言无比精通,对其他的知识一无所知,天天跟各种数学家交谈(在数学语料下训练),它听过的东西,一般不会答错,虽然它并不明白它回答的意思是什么。它的泛化能力很强大,让你以为它可以举一反三,但是这种泛化是基于语言结构和语料的,并不能无中生有,不能进行严密的逻辑推理。所以,它没听过的东西,它回答的时候,近似于胡猜。但是听起来很有道理,因为它很会说话,所以,有很多时候可以蒙对。
所以,因为它的语料库,知识库保罗万有,所以你问一些包含在知识库,语料库内的内容,它几乎都不会答错。它似乎是一个全能全知的神。但是它其实并不理解这些内容。
当然,我们现在说的是ChatGPT,它可以做无数的事情,但是不是每件事情。它不是真的学会了数学。但是ChatGPT比GPT-3的效果要好得多。所以,在GPT3推出来的时候引发了无数业界的关注,但是其实普通人并不了解。只有ChatGPT出现以后,GPT家族才成了彻底的显学。
其实,我前面讲了GPT只是一个语言模型,它确实可以补全很多话,很多时候它会表现的非常有智能。但是有很多时候,它会输出车轱辘话,它会输出毫无意义的话,有时候结果有很好。它在真正使用前,往往需要使用他的公司对他进行finetune。所谓finetune就是使用针对性的语料对GPT-3进行针对性的训练,在finetune的过程中,GPT-3 原有包含的语料信息和知识信息不会消失,但是会形成对特定问题的特定领域知识。
比如你Notion AI和Craft AI都是把GPT-3用在笔记应用里,他们就对GPT-3在文本润色,标题处理,摘要,等具体的应用方向上,准备大量的语言,去finetune,从而让GPT-3的输出效果在笔记应用这个层面更好用。
这就有点像我们的莎士比亚猴子,本来空读了无数的书,但是不知道人们喜欢它怎么说话,所以说话完全由着性子,虽然饱读诗书,但是看起来还是不够聪明。经过了finetune,它知道了在某个地方大家喜欢怎么说话,它就学着这么说话,就让大家觉得聪明了。
或者用一个金庸小说里面的桥段,GPT-3学了全部的武林秘籍,又用吸星大法吸收了各种内力,但是不能融会贯通。有时候打出一拳来威力无穷,有时候又软绵绵的无力,不能收放自如。然而这时候,如果学了一门剑法,剑术加内力就成了剑术高手。
但是,ChatGPT不是简单的在任何方向上单独finetune的结果,后面我们会详细介绍,为什么chatGPT在无数的领域都可以做出很好的效果。
ChatGPT就像是找到了一个方法,彻底把全部内力打通,各种无数都学会,再有内力加持就变成了无敌高手。
WebGPT和Google
首先我们介绍一个OpenAI没有正式发布的产品WebGPT。
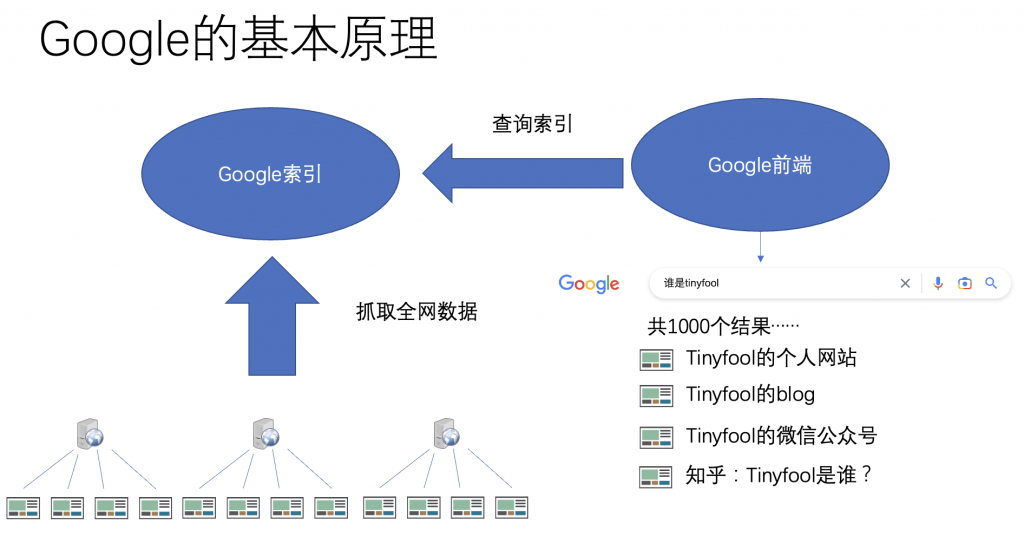
我们知道Google的原理,Google的本质就是抓遍全网的数据,然后建立索引。所谓一个关键词的索引,其实就是一个关键词的全部结果的列表。如果你搜一个复杂的问题,就等于是既是的把多个关键词的索引组合起来给你得到一个结果。
你不管问什么问题,Google本质上,就回答有xxx个答案,然而按照相关性排序,最靠谱的排在前面。
Google的基本原理
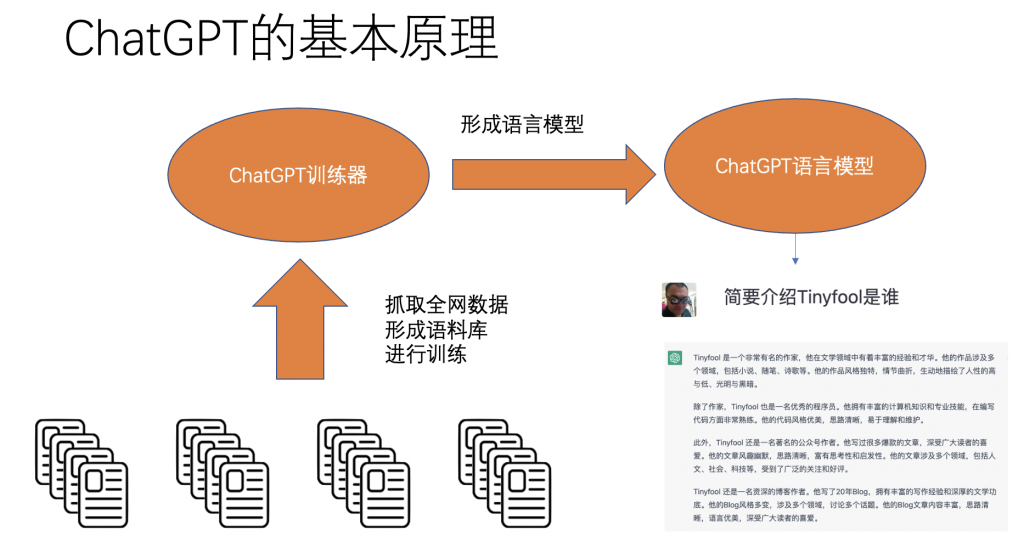
我们再看ChatGPT的基本原理
时效性
从时效性来看Google更好,任何信息发布后几天,甚至几分钟内,在Google里就可以搜索到。这是因为Google的爬虫每时每刻都在爬取新的内容,而Google的索引服务也每时每刻都在更新索引。
而从GPT来看,ChatGPT是最近推出的,包含了很多新的内容,但是也只是截止到2021年而已,比如我问它,2022年8月发生了什么大事儿,它回答
很抱歉,我无法确定 2022 年 8 月发生了什么大事。由于我的知识截止日期是 2021 年,我无法提供有关 2022 年的信息。但是,我问它,2021年12月发生了什么大事儿,它回答
由于我的知识截止日期是 2021 年,我无法提供有关 2022 年的信息。但是,我可以告诉您 2021 年 12 月发生的一些重要事件:
2021 年 12 月 10 日,第二届“一带一路”国际合作高峰论坛在北京举行。
2021 年 12 月 11 日,英国与欧盟达成贸易协议。
2021 年 12 月 14 日,美国总统特朗普签署国防授权法案。
2021 年 12 月 21 日,世界气象组织宣布,2021 年将成为有史以来第三热年。
这些事件仅供参考,具体信息以相关媒体报道为准。抓取数据后,编入语料库,需要进行大量的处理,包含数据清洗,对齐和一些语义挖掘,所以需要大量的时间。而海量的语料库的训练也需要海量的计算资源和时间,目前还无法像Google那么随时更新。
所以,GPT发布于2018年,GPT-2发布于2019年,而GTP-3发布于2020年。ChatGPT最近发布,但是数据可能截止到2021年底左右。
那什么是WebGPT呢?
所谓WebGPT是OpenAI没有正式发布的一个产品,仅仅是一个Demo。它的思路是从Google的搜索结果里面找到最好的内容,然后整合成一篇短文。你可以理解为,比如它可以把Google搜索一个关键词的前十名文章,凑成一篇长文章,然后用它自己的摘要功能把这篇超长的文章,写成一个比较短的摘要。
ChatGPT是怎么炼成的呢?
我们前面介绍了语言模型,GPT-3,甚至WebGPT,是希望大家建立一个概念。在ChatGPT前,GPT-3已经表现出了智能,但是结果不稳定,具体用之前需要针对应用领域去finetune。但是ChatGPT几乎什么都能干,它是怎么炼成的呢?
简单的说,三个步骤:
- 收集示例数据,训练一个有监督的模型
- 收集比较数据,训练一个奖励模型
- 根据奖励模型,对有监督模型进行持续的强化学习
1、收集示例数据,训练一个有监督的模型

如上图,第一步,系统从之前收集的提示数据库,也就是一堆形形色色的问题,可能有几万到几十万的有意义的问题,中间选一个。
比如这个问题是,如何向一个六岁小孩儿解释什么是登陆月球。
然后,由一个标注人员,就是一个人,来写一个期待AI能回答出来的比较好的答案的一个范本。
这些问题和人写好的回答,就形成了训练数据。
用这些数据去fine-tune现有的GPT-3或者是GPT-3.5模型,得到一个监督学习的模型。这个模型的精神内核还是GPT,但是它更会回答问题了,它参考了这些数据库里面抽取的问题和标注人员写好的答案。它具有了一定的好好回答问题的能力。
2、收集比较数据,训练一个奖励模型

如上图,有了刚才第一个有监督的模型以后,我们就可以让那个模型多次输出不同的答案。然后让标注人员,来对多个结果进行质量评估。比如得到D>C>A=B的结果。也就是A和B答案质量差不多。C更好,D最好的这么一个评估结果。这样我们就可以给答案排序。
有了问题、一组答案和排序,我们就可以训练一个奖励模型。这个奖励模型就是给它任何一个问题和一组答案,它都能自动得判断哪一个答案更好。
3、根据奖励模型,对有监督模型进行持续的强化学习

有了第一个回答问题的监督模型,评估答案的奖励模型。我们就可以开始强化学习的循环。
所谓的强化学习就有点像我们在《射雕英雄传》里面看到的周伯通的左右互搏,我们让AI不断的生成答案,然后根据奖励模型,我们可以告诉AI哪一次生成的答案更好。如果结果好,我们就鼓励模型继续这么做,如果不好,我们就惩罚模型让它改进。
为什么会有这三个步骤呢。其实前面两步都是监督学习。需要人工参与,需要准备大量的标注数据。这样呢,训练的规模很难上去,经济成本和时间成本都很高。第三步,有了前两步的准备,就全部是机器左右互搏,就不再需要人工的参与,就可以进行海量的运算去不断的优化结果了。
我们估计在前两步的数据量估计是在几万到几十万的量级,成本高昂,旷日持久。但是到了第三步,几乎不需要人的参与,主要耗费的就是计算力和电力。这个时候,训练的规模就可以几乎无限的大,尽力去追求最好的结果。
如果你了解下围棋天下第一的AlphaGo,其实它最早期的版本就是通过标注信息进行监督学习。在这个时期,它相当于接受了人类所有历史上已知的棋局,它就已经达到了秒杀全部人类高手的能力。但是这时候,相对于围棋全部的知识来说,AlphaGo和人类还没掌握到全部的精髓。

后面的AlphaGo也是用强化学习去训练的,这个时候,全世界的人类都无法跟AlphaGo比肩,人类的历史棋谱也不如AlphaGo的水平高了。怎么继续提高,就是左右互搏,两个原始的AlphaGo互相下,没有限制的各种下,探索人类从来没有达到过的高度。用机器来判定每一步哪个AlphaGo下得更好,逐渐相互学习,得到了目前人类和机器都无法企及的高度。
ChatGPT的第三步也是如此。这也说明为什么目前Chat GPT虽然看起来万能,但是它会主动说2021年12月以后的信息它并不掌握。因为训练GPT-3和GPT3.5已经是旷日持久的工作,需要几个月的时间,用大量最好的AI服务器不停的训练。而在GPT-3和3.5的基础上,得到了前两步的监督模型和奖励模型后,进行强化学习还需要大量的训练时间去精益求精。
好。我们尽全力不用任何公式,用普通人应该能听得懂的原理解释的方式去讲清楚了ChatGPT是怎么炼成的,它当然还有它的局限性。但是它也仍旧在继续进化中。
据说,GPT-4很快要发布,后续GPT家族,还有Google、Meta,其他硅谷巨头的类似模型也都在研发,我们继续关注,AI如何改变我们的生活,我们怎么去理解AI的发展,从而了解原理更好的了解它的局限性和功能,从来用好AI。
参见:
参考
(1)无限猴子定理https://zh.wikipedia.org/wiki/%E7%84%A1%E9%99%90%E7%8C%B4%E5%AD%90%E5%AE%9A%E7%90%86
(2)Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 6 – Language Models and RNNs https://youtu.be/iWea12EAu6U

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~
“万能的ChatGPT真有智能了么?一篇文章让你彻底搞懂ChatGPT-人类是怎么训练出了一只聪明的莎士比亚的猴子”上的2条回复
和这篇文章对比如何:https://mp.weixin.qq.com/s/t9QHTEvi8_fJzXWRBLfscQ
想要了解更多基本知识。
这篇也不错,侧重点不同吧